色妈妈 谢赛宁新作:表征学习有多伏击?一个操作刷新SOTA,DiT教师速率暴涨18倍
发布日期:2024-12-07 22:11 点击次数:162
 色妈妈
色妈妈
著作转载于新智元
扩散模子若何粉碎瓶颈?资本高又难教师的DiT/SiT模子若何赞助服从?
关于这个问题,纽约大学谢赛宁团队最近发表的一篇论文找到了一个全新的切入点:赞助表征(representation)的质地。
论文的中枢大要就不错用一句话综合:「表征很伏击!」

用谢赛宁的话来说,即使只是想让生成模子重建出颜面的图像,仍然需要先学习渊博的表征,然后再去渲染高频的、使图像看起来更好意思不雅的细节。
这个不雅点,Yann LeCun之前也屡次强调过。

有网友还在线帮谢赛宁想标题:你这篇论文不如就叫「Representation is all you need」(手动狗头)

由于不雅点一致,这篇不息也取得了同在纽约大学的Yann LeCun的转发。

当使用自监督学习教师视觉编码器时,咱们知谈一个事实,使工具有重建亏损(reconstruction loss)的解码器的服从远远不如具有特征展望亏损(feature prediction loss)和崩溃防患机制的合资镶嵌架构。
这篇来自纽约大学谢赛宁团队的论文标明,即使只对生成像素感敬爱敬爱(举例,使用扩散Transformer生成漂亮的图片),包含特征展望亏损亦然值得的,以便解码器的里面暗意不错基于预教师的视觉编码器(举例 DINOv2)进行特征展望。
REPA的中枢想想十分浮浅,等于让扩散模子中的表征与外部更渊博的视觉表征进行对王人,但赞助服从十分显耀,颇有「他山之石,不错攻玉」的意味。
只是是在亏损函数添加一项相似度最大化,就能将SiT/DiT的教师速率赞助快要18倍,还刷新了模子的SOTA性能,在ImageNet 256x256上结束了最先进的FID=1.42。
谢赛宁暗意,刚看到现实遣散时,他我方也被忌惮到了,因为嗅觉并莫得发明什么全新的东西,而只是意志到了,咱们简直实足不睬解扩散模子和SSL措施学习到的暗意。
1
论文简介

论文地址:https://arxiv.org/abs/2410.06940
技俩地址:https://sihyun.me/REPA/
在生成高维的视觉数据方面,基于去噪措施(如扩散模子)或基于流的生成模子,还是成为了一种可膨大的路线,并在有挑战性的的零样本文生图/文生视频任务上取得了十分成功的遣散。
最近的不息标明,生成扩散模子中的去噪流程不错在模子里面的笼罩情景中引入有利料的暗意,但这些暗意的质地现在仍过期于自监督学习措施,举例DINOv2。
作家以为,教师大范围扩散模子的一个主要瓶颈,就在于无法灵验学习到高质地的里面暗意。
如若能够衔尾高质地的外部视觉暗意,而不是只是依靠扩散模子来孤立学习,就不错使教师流程变得更容易。
为了结束这少许,论文基于经典的扩散Transformer架构,引入了一种浮浅的正则化措施REPA(REPresentation Alignment)。
浮浅来说,等于将去噪采聚会从噪声输入
得到的笼罩情景𝐡的投影,与外部自监督预教师的视觉编码器从干净图像𝐱取得的视觉暗意𝐲*进行对王人。
这么一个十分直给的战略,却取得了惊东谈主的遣散:运用于流行的SiT或DiT时,模子的教师服从和生成质地都得到了显耀提高。
具体来说,REPA不错将SiT的教师速率加速17.5×以上,以不到40万步的教师量匹配有700万步教师的SiT-XL模子的性能,同期结束了FID=1.42的SOTA遣散。
1
REPA:使用表征对王人的正则化
调和视角的扩散模子+流模子
由于论文但愿同期优化基于流的模子SiT和基于去噪的扩散模子DiT,因此最初从调和的立地插值视角,对这两种模子进行简要的回归。
洽商在t∈[0,T]的合资时候步中,对数据𝐱*~p(𝐱)使用高斯散布ε~𝓝(0,𝐈)添加立地杂音:
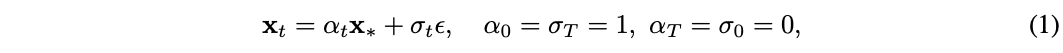
其中,αt和σt远隔暗意t的递减和递加函数。在公式(1)给定的流程中,存在一个带有速率场(velocity field)的概率流常微分方程:
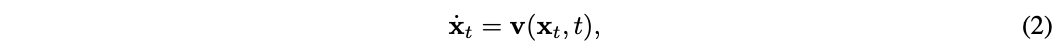
其中t步时的散布就等于角落概率pt(𝐱)。
速率𝐯(𝐱,t)不错暗意为如下两个条目守望之和:
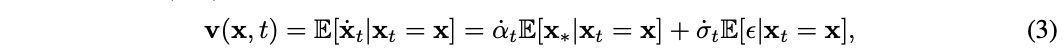
这个值不错通过最小化如下教师主义得到近似值𝐯θ(𝐱,t):
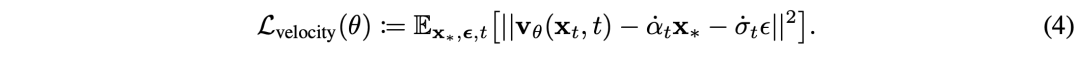
同期,还存在一个反向的立地微分方程(SDE),带有扩散扫数wt,其中的角落概率pt(𝐱)与公式(2)相符:
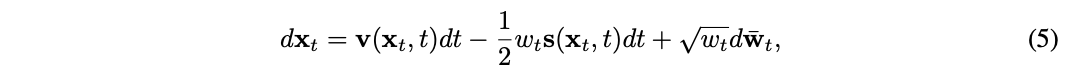
其中,𝐬(𝐱t,t)是一个条目守望值,界说为:
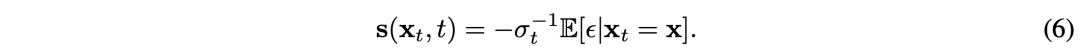
对率性t>0,都不错通过速率𝐯(𝐱,t)野心出𝐬(𝐱,t)的值:
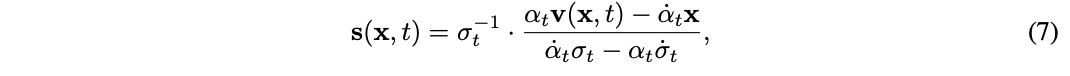
这标明,数据𝐱t也不错通过求解公式(5)的SDE来以另一种形式生成。
以上界说对访佛的扩散模子变体,举例DDPM,相同适用,只是需要将合资的时候步翻脸化。
措施概述
令p(𝐱)为数据𝐱∈𝓧的未知主义散布,咱们的教师主义等于通过模子对数据的学习得到p(𝐱)的近似。
国产巨乳为了缩小野心资本,最近流行的「潜在扩散」措施(latent diffusion)建议学习潜在变量𝐳=E(𝐱)的散布p(𝐳),其中E暗意来自预教师自编码器(举例KL-VAE)中的编码部分。
要学习到散布p(𝐳),就需要教师扩散模子𝐯θ(𝐳t,t),教师主义是进行速率展望,具体措施如上一节所述。
放在自监督暗意学习的布景中,不错将扩散模子算作编码器fθ:𝓩⭢𝓗息争码器gθ:𝓗⭢𝓩的组合,其中编码器正经隐式地学习到暗意𝐡t以重建主义𝐯t。
关联词,作家建议,用于生成的大型扩散模子并不擅长表征学习,因此REPA引入了外部的语义丰富的暗意,从而显耀赞助生成性能。
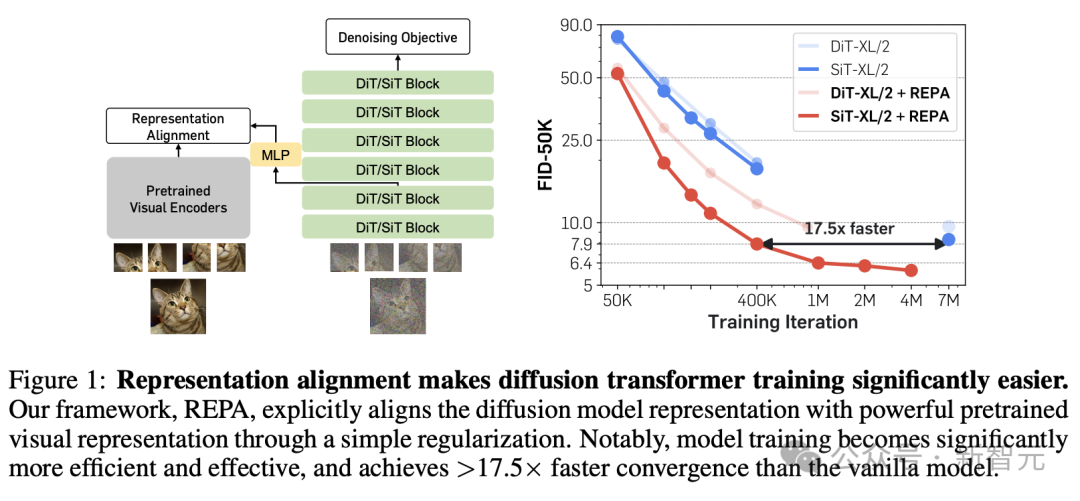
REPA措施概述
模子不雅察
扩散模子是否真的不擅长表征学习?这需要更进一时局不雅察模子智商细目,为此,不息东谈主员测量并比对了diffusion transformer和刻下的SOTA自监督模子DINOv2之间的表征差距,包括语义差距和特征对王人两种角度。
语义差距
从图2a可知,预教师SiT的笼罩层暗意在第20层达到最好情景,这与之前的不息遣散相符,但仍远远过期于DINOv2。
特征对王人
如图2b和2c所示,使用CKNNA值测量SiT和DINOv2之间的表征对王人进程后发现,SiT的对王人服从会跟着模子增大和教师迭代步数加多而逐步改善,但即使加多到7M次迭代,和DINOv2之间的对王人进程仍然不及。
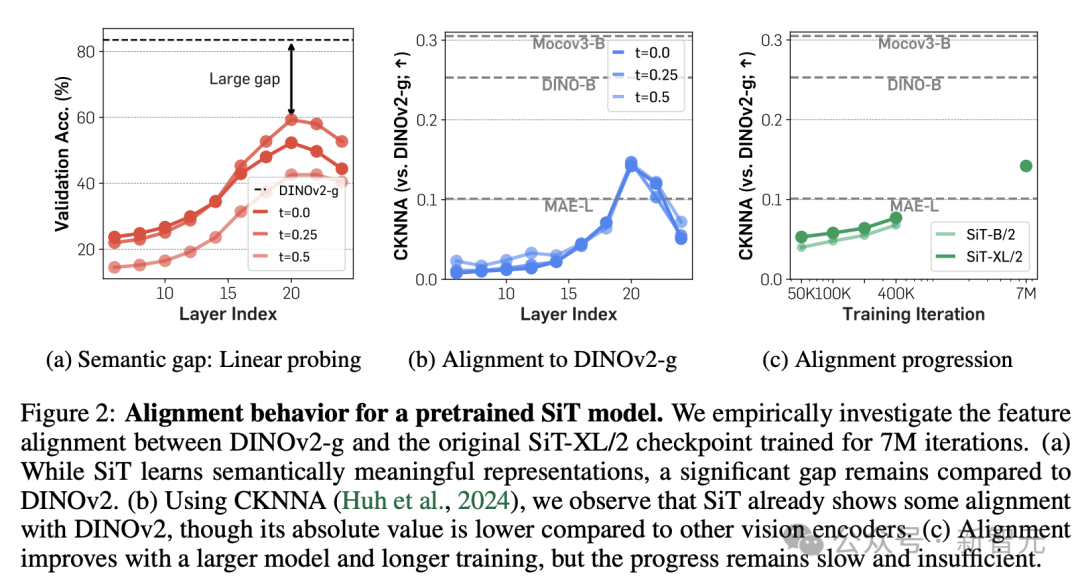
事实上,这种差距不仅在SiT中存在,凭据附录C.2的现实遣散,DiT等其他基于去噪的生成式Transformer模子也存在访佛的问题。
减弱表征差距
那么,REPA措施究竟若何减弱这种表征差距,让diffusion transformer在噪声输入中也能学到有用的语义特征?
界说N,D远隔暗意patch数目预教师编码器f的镶嵌维度,编码器输入为无噪声的图像𝐱*,输出为𝐲*=f(𝐱*)∈ℝN×D。
Diffusion transformer将编码器输出𝐡t=fθ(𝐳t)通过一个可教师的投影头hφ(MLP)投影为hφ(𝐡t)∈ℝN×D。
之后,REPA正经将hφ(𝐡t)与𝐲*进行对王人,通过最大化两者间的patch间相似度:
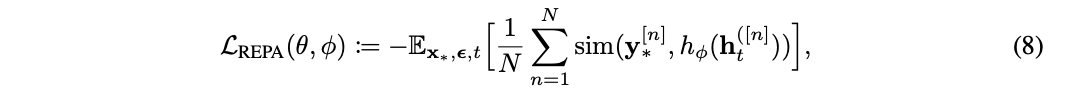
在本色结束中,将这一项添加到公式(4)界说的基于扩散的教师主义中,就得到总体的教师主义:
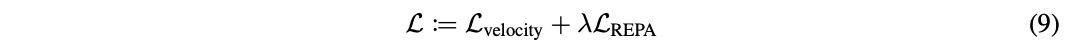
其中超参数λ>0用于戒指模子在去噪主义和表征对王红尘的衡量。
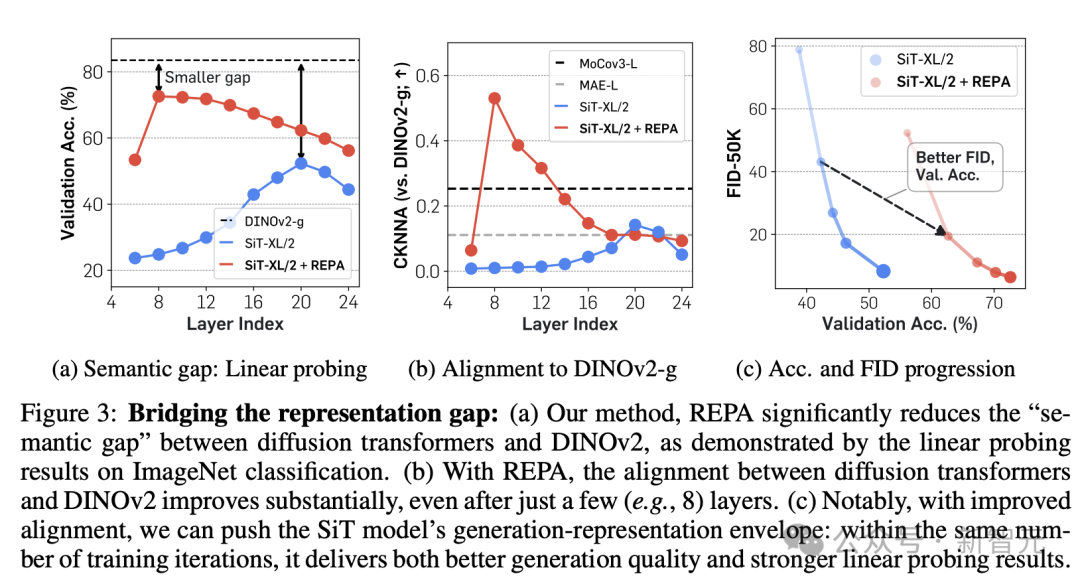
从图3遣散可知,REPA减少了暗意中的语义差距。
风趣的是,使用REPA后,仅对王人前几个Transformer块就能结束填塞进程的暗意对王人,从而让diffusion transformer的靠后层专注于拿获高频细节,从而进一步提高生成性能。
1
现实遣散
为了考证REPA措施的灵验性,现真实两种流行的扩散模子教师主义(即𝓛velocity)上进行了现实,包括DiT中校正后的DDPM和SiT中的线性立地插值,但本色中也相同不错洽商其他的教师主义。
所用模子默许严格革职SiT和DiT的原始结构(除非有终点评释),包括B/2、L/2、XL/2三种参数建树,如表1所示。

以下现实旨在回复3个问题:
- REPA能否显耀赞助diffusion transformer的教师?
- REPA在模子范围和表征质地点面是否具有可膨大性?
- 扩散模子的表征能否和多种视觉表征进行对王人?
REPA赞助视觉缩放
最初相比两个SiT-XL/2模子在前400K次迭代时期生成的图像,它们分享疏导的噪声、采样器和采样步数,但其中使用REPA教师的模子露馅出更好的进展。
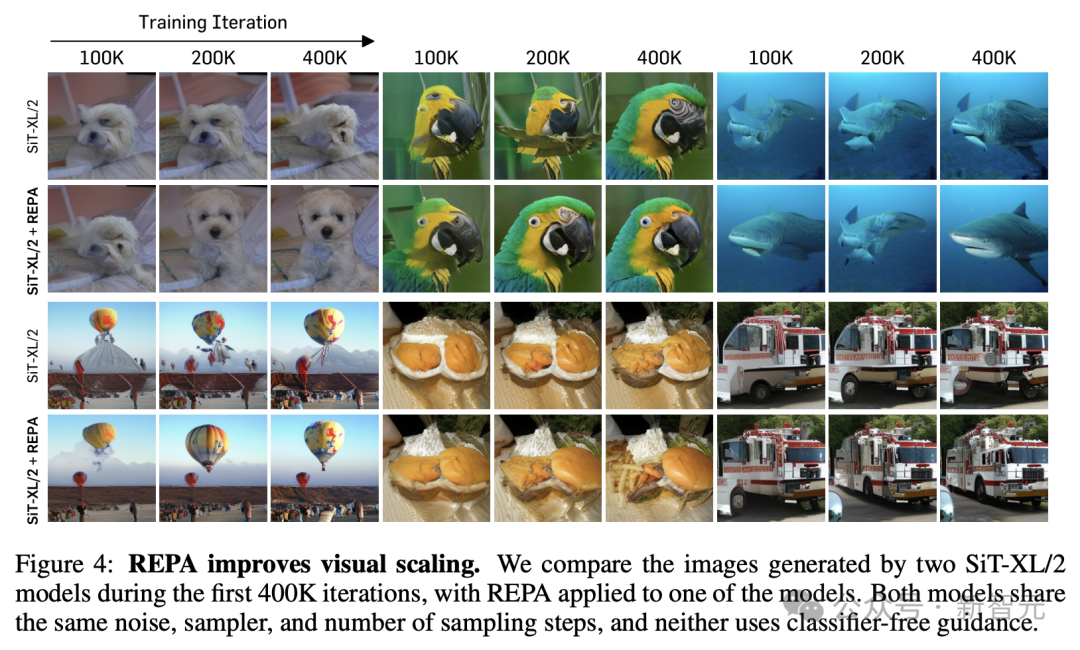
REPA在各个方面都展现出了渊博的可膨大性
不息东谈主员还转变了预教师编码器和Diffusion Transformer的模子大小来历练REPA的可膨大性。
图5a遣散标明,与更好的视觉暗意相衔尾不错改善生顺利率和线性探伤的遣散。
此外,如图5b和c所示,加多模子大小不错在生成和线性评估方面带来更快的收益,也等于说,模子范围越大,REPA的加速服从越显然,进展出了渊博的可膨大性。
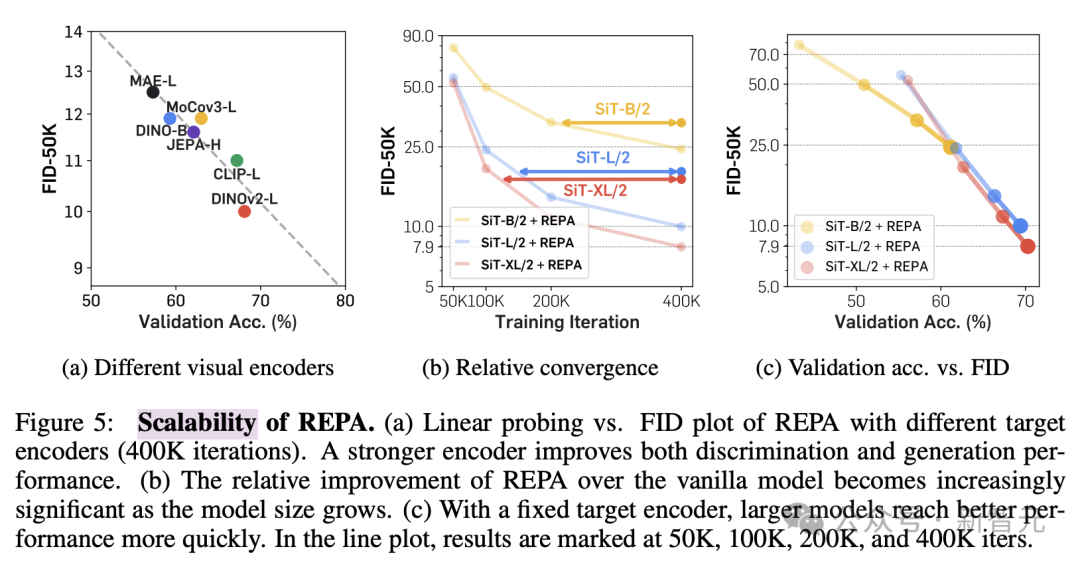
REPA显耀提高教师服从和生成质地
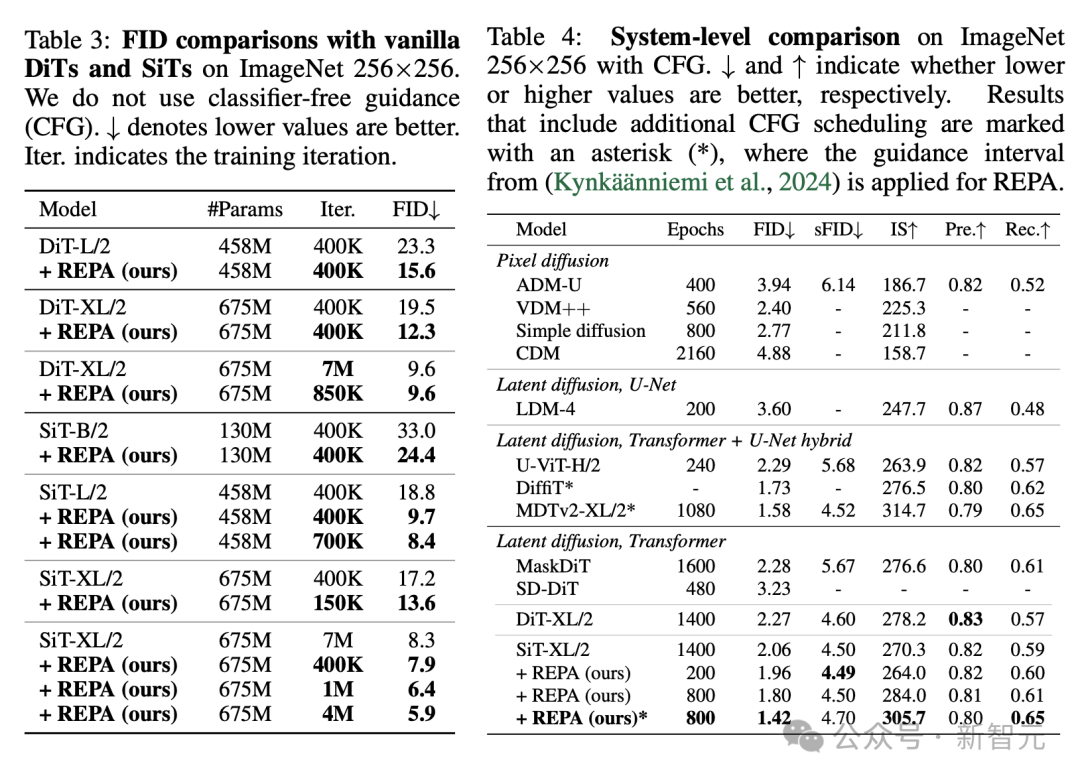
终末,论文相比了平时DiT或SiT模子在教师中使用REPA前后的FID值。
在莫得指导的情况下,REPA在400K次迭代时结束了FID=7.9,优于平时模子在7M次迭代后的性能。
此外,使用无分类器指挥时,带有REPA的SiT-XL/2的性能优于SOTA性能(FID=1.42),同期迭代次数减少了7倍。
1
作家先容
Sihyun Yu

本文一作Sihyun Yu是KAIST(韩国科学技巧院)东谈主工智能专科终末一年的博士生,此前他相同在KAIST取得了数学和野神思科学的双专科学士学位。
他的不息主要鸠集在减少大型生成模子教师(和采样)的内存和野心职守,其中,对大范围且高效的视频生成终点感敬爱敬爱;博士时期,他还曾在英伟达和谷歌不息院担任实习生。
参考辛劳:
https://x.com/sainingxie/statdus/1845510163152687242色妈妈
栏目分类